Finding Amazon S3 Buckets in the Wild

Introduction⌗
Amazon Simple Storage Service (Amazon S3) is an object storage service used by a lot of companies to store data of various different types in a container called a bucket. These data range from the company’s logo to Personally identifiable information of the users. Developers sometimes don’t configure the buckets correctly and make them available for public use. In this blog I’ll show you:
- How to find buckets
- How to exploit them
How to find buckets belonging to a company⌗
Google Dorking⌗
When you google something, google generally shows you a lot of results that are generally sorted in the most viewed order. It doesn’t matter whether they are useful or not, google follows the policy “if it was viewed by a lot of people it might be useful for you too” and that is the case most of the time. But sometimes you want to restrict the search results to specific results only or you want to filter out the garbage and there we use google dorks. They are nothing but keywords used to filter the results to only the apt matches.
Some of the common google dorks to find s3 buckets
-
site:target.tld intext:"s3.amazonaws.com"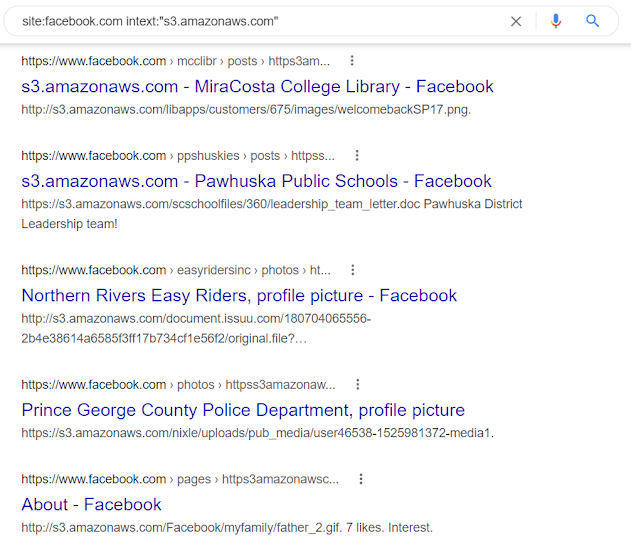
What this does is, it finds all the occurrence of the text
"s3.amazonaws.com"on all the sites that containsfacebook.comin it (or on*.facebook.com). -
site:s3.amazonaws.com "target"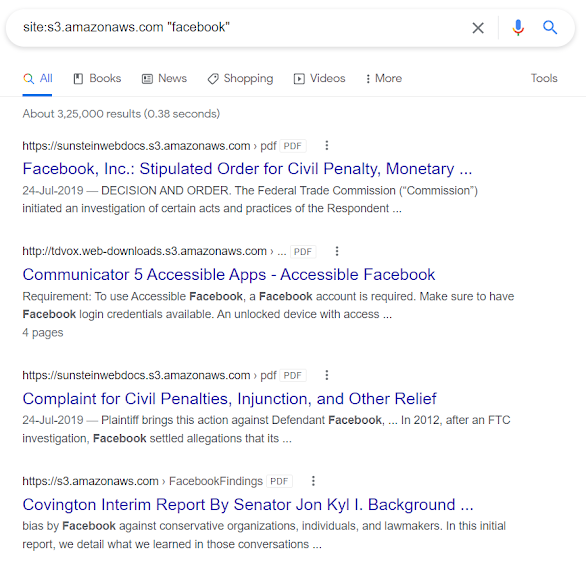
This shows all the URLs from the sites that contain
s3.amazonaws.com(*.s3.amazonaws.com) and has the text"facebook". -
site:s3.amazonaws.com inurl:target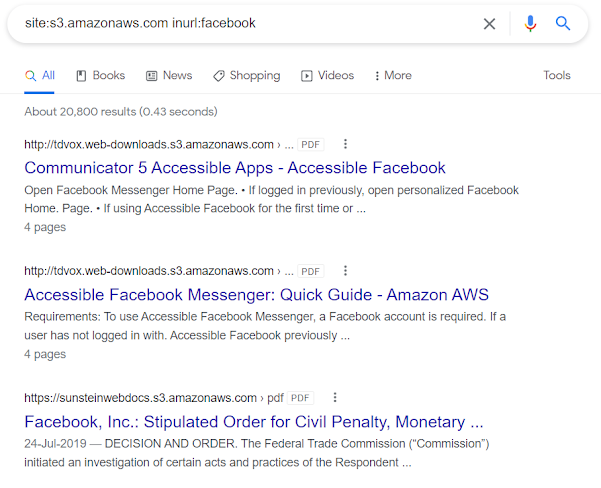
Here we are making the assumption that the URL of the s3 bucket belonging to facebook will contain the keyword
facebookin it. Here you can get a bit creative and see how the company that you are hacking on is naming their assets. You might find some pattern in their subdomain names and can use a similar kind of google dork to find a much more suitable match.
Automating finding S3 buckets⌗
Amazon S3 has a bucket naming convention that has to be followed when you are making a bucket.

Based on this @nahamsec wrote a tool lazys3 which uses a wordlist and tries different permutations keeping the naming rules in mind and tries to find s3 buckets belonging to the specific company. This tool was written more than 4 years ago and is quite slow so I thought to develop on it and make my own tool to automate this process.
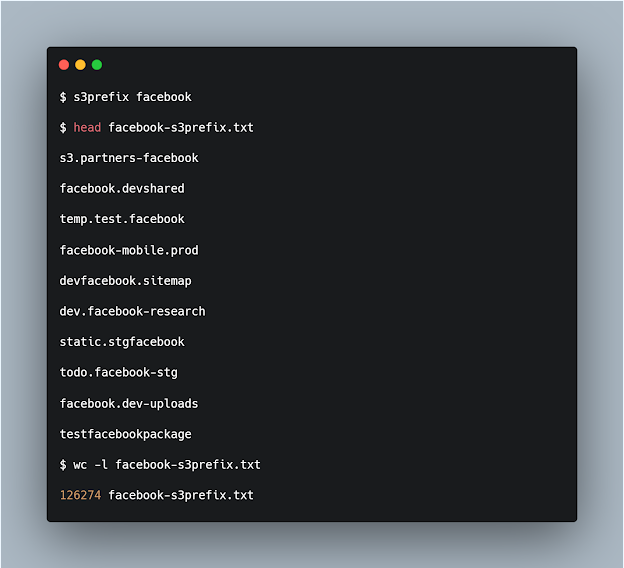
Inspired by lazys3, I wrote my own tool called s3prefix, which contains the wordlist that lazys3 uses and some more words that I found from this talk by @XSaadAhmedX. The wordlist is called common_bucket_prefixes.txt and can be found in the github repository. It prints a wordlist of different possible permutations following the Amazon S3 naming rules. You can use this wordlist (called target-s3prefix.txt) to fuzz https://FUZZ.s3.amazonaws.com using another tool called ffuf to find S3 buckets. The wordlist generated by my tool contains around 125,000 possible permutations for an S3 bucket belonging to the company.
I tried to make a tool called gos3 that would automate the fuzzing part too but ffuf was doing the job much faster and smoother.
So install the s3prefix tool as mentioned in the readme of the repository and copy the common_bucket_prefixes.txt file to .config directory in your home directory.
Create the wordlist required for fuzzing:
s3prefix target
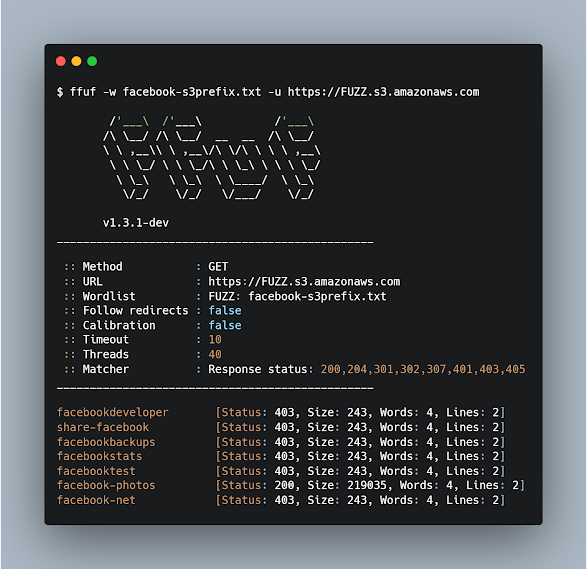
Fuzz https://FUZZ.s3.amazonaws.com using ffuf:
ffuf -w s3prefix-target.txt -u https://FUZZ.s3.amazonaws.com
Finding S3 buckets in js files⌗
Companies using S3 buckets to store user data mention the URL in JS files. Although available on internet and can be seen by anyone we can’t search for them using google dorks. So we need to look at the js files explicitly and search for s3.amazonaws.com. To automate this I made a tool, called subjs, to which if you provide a list of js files it will print all the S3 bucket URLs.
cat jsfiles.txt | subjs -s3
You can combine it with waybackurls too:
echo "target.tld" | waybackurls | grep '\.js' | subjs -s3
Exploiting misconfigured S3 buckets⌗
First you need to download aws cli tool and configure it with your access key id and secret key which you can get by following the directions described in this doc.
Once you have your aws cli configure and you find an S3 bucket URL the first thing to do is to open it on a browser. Let’s take an example:
Here you can see facebookdeveloper is a bucket name that results in a 403 access denied as can be seen from the Status: 403 in ffuf results.
Still we open the URL https://facebookdeveloper.s3.amazonaws.com/ in a browser.
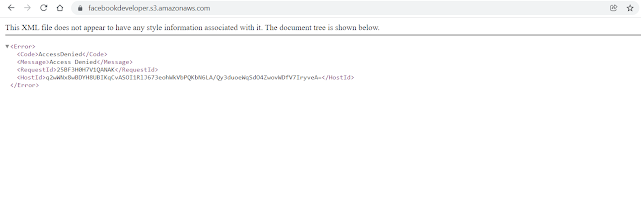
Here too we get a 403 access denied response.
So we try to access this bucket using aws cli:
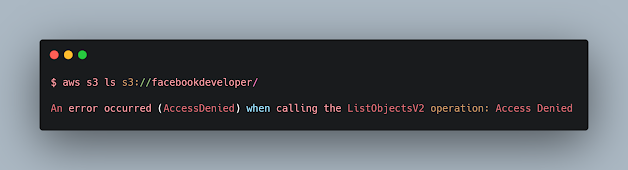
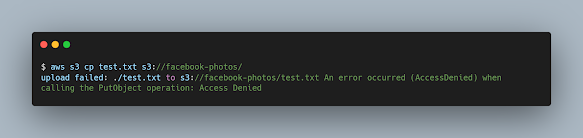
And here too we get Access Denied which means that the bucket is configured correctly.
Now let’s look at the bucket with bucket name facebook-photos it has the status code 200 in ffuf response.
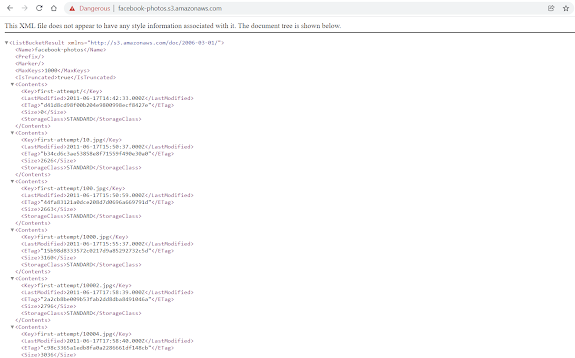
We can see the files in this bucket but when we try to access them from the browser we get a 403 Access Denied error.
Using aws cli tool: So we can access the directories in this bucket. Now there are some things that you can try on this bucket:
-
Read files and see if there exists some confidential information. This doesn’t contain anything that might look confidential.
aws s3 ls s3://facebook-photos/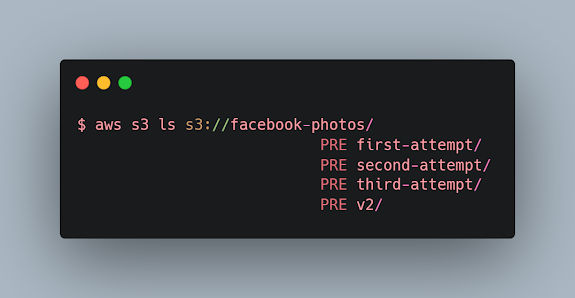
-
Try to see if you can read something from the files, in this bucket it is not possible to read anything.
aws s3 cp s3://facebook-photos/v2/starting-at-1004000/1004001.jpg ./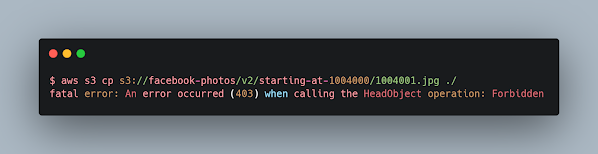
-
Trying to upload a file in the bucket. Uploading is not possible either.
aws s3 cp test.txt s3://facebook-photos/